
In today’s rapidly evolving technological landscape, the term “Generative AI” has become a ubiquitous buzzword, a topic discussed in every tech conversation. But what precisely is generative AI, and how does it work? How can you leverage AWS services to tap into this transformative technology? Join us on a journey through today’s blog as we demystify the world of generative AI, shedding light on its inner workings and the transformative impact it can have across industries. And, most importantly, discover how you can leverage, as in our demonstration, AWS Bedrock—a revolutionary AWS service that empowers you to build remarkable generative AI applications, unlocking your company’s full potential.
Generative AI, the Next Big Step
Generative AI is not merely a passing trend; it’s a force poised to add up to $4.4 trillion in value to the global economy, as highlighted by a McKinsey report1. Its applications span numerous domains, including customer operations, marketing, sales, software engineering, research, and development. It even extends its transformative reach within your organization, enhancing productivity and accelerating processes.
On the creative front, generative AI can weave together a diverse array of media content, from generating images to crafting blog posts and personalized email communications to your customers. On the technical side, you’ve likely witnessed impressive integrations such as GitHub Copilot, which assists developers in generating code suggestions based on their code and comments. But before we dive in, let’s set up the stage into how we have generative AI.
Evolution to Generative AI
In the intricacies of generative AI, it’s essential to establish a solid foundation by examining the broader landscape of AI. The term “AI” often seems enigmatic, and to comprehend it better, we’ll start with a fundamental question: What is AI, exactly?
AI serves as an encompassing term for a diverse array of advanced computer systems. However, for a more precise perspective, let’s narrow our focus to “machine learning.” Much of what we encounter in today’s AI landscape can be categorized as machine learning—imparting computer systems with the ability to learn from examples. When we speak of machines learning from examples, we often refer to them as “neural networks.” These neural networks acquire knowledge through exposure to numerous examples. For instance, teaching a neural network to recognize the Eiffel Tower entails feeding it a vast and varied collection of images capturing the landmark from various angles and perspectives. Through this extensive training and appropriate labeling, the model gains the ability to distinguish the Eiffel Tower in a photograph from other elements, enabling swift and accurate recognition.
Language Models
In the context of Generative AI, the process shares some similarities, primarily revolving around language models, a unique category of neural networks. Language models excel in anticipating the next word within a sequence of text. To enhance their predictive capabilities, these models undergo extensive training with substantial volumes of textual data as well.
One method for refining a language model involves exposing it to a more extensive corpus of text, mirroring how humans expand their knowledge through study. Consider, for example, the phrase “I am flying on an…”; a well-trained language model can accurately predict “I am flying on an airplane.” As training deepens, the model’s proficiency grows, enabling it to generate nuanced responses and offer valuable insights into the probable continuation of the sentence.
Evidently, this forms the revolutionary foundation for what we now refer to as “Generative AI.” Building upon the capabilities of Large Language Models (LLMs), which can have up to hundreds of billions of parameters, Generative AI excels at creating entirely new content based on the knowledge it has accumulated. Currently, Generative AI extends its reach beyond text, delving into various media formats, including images, audio, and even video. This raises the question: how can we tap directly into this technology without the need for an extensive data corpus or even stored data to train and deploy?
Amazon Bedrock
Amazon Bedrock opens the doors to a world of generative AI possibilities, offering a diverse array of features and foundational models that empower developers and businesses to harness the full potential of this transformative technology.
Choice of Leading Foundation Models: With Amazon Bedrock, you gain access to a versatile array of high-performing Foundation Models (FMs) sourced from top AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. This diversity allows you to explore a wide spectrum of models within a single API, providing the flexibility to adapt and experiment without extensive code changes.
Effortless Model Customization: Tailor these models to your unique needs with ease, all without writing a single line of code. Amazon Bedrock’s intuitive visual interface empowers you to customize FMs using your own data. Simply select the training and validation datasets stored in Amazon Simple Storage Service (Amazon S3) and fine-tune hyperparameters for optimal model performance.
Fully Managed Agents: Break new ground with fully managed agents, capable of dynamically invoking APIs to execute complex business tasks. From travel booking and insurance claim processing to crafting ad campaigns and inventory management, these agents extend the reasoning capabilities of FMs, offering a solution for a myriad of applications.
Native RAG Support: Amazon Bedrock is fortified with Knowledge Bases, enabling secure connections between FMs and your data sources for retrieval augmentation. This feature enhances the already potent capabilities of FMs, making them more knowledgeable about your specific domain and organization.
Data Security and Compliance: Amazon Bedrock prioritizes data security and privacy, having achieved HIPAA eligibility and GDPR compliance. Your content remains confidential, not used to enhance base models or shared with third-party providers. Data encryption, both in transit and at rest, ensures the utmost security, and AWS PrivateLink seamlessly establishes private connectivity between FMs and your Amazon Virtual Private Cloud (Amazon VPC), safeguarding your traffic from exposure to the Internet.
Why Amazon Bedrock?
Amazon Bedrock is a comprehensive, fully managed service that revolutionizes generative AI development. Offering a selection of high-performing FMs from leading AI companies, it simplifies the process of building generative AI applications while preserving privacy and security. Experiment with top FMs, customize them with your data, create managed agents for complex tasks, and seamlessly integrate generative AI capabilities into your applications, all without the need to manage infrastructure. With Amazon Bedrock, you can confidently explore the limitless possibilities of generative AI using the AWS services you already know and trust. Below are the models offered as of November 2023:
Amazon Titan: Ideal for text generation, classification, question answering, and information extraction, with an added text embeddings model for personalization and search.
Jurassic: Specializing in instruction-following models for various language tasks, including question answering, summarization, and text generation.
Claude: A model for thoughtful dialogue, content creation, complex reasoning, creativity, and coding, grounded in Constitutional AI and harmlessness training.
Command: Tailored for text generation, optimized for business use cases, based on prompts.
Llama 2: Offers fine-tuned models, particularly well-suited for dialogue-centric use cases.
Stable Diffusion: An image generation model that produces unique, realistic, and high-quality visuals, including art, logos, and designs.
And this is merely the starting point, considering that AWS Bedrock was unveiled in September 2023.
Amazon Bedrock in Action
Now, without further ado, let’s demonstrate the rapid application of Amazon Bedrock models to implement Retrieval Augmented Generation (RAG). RAG is an architectural approach that enhances the capabilities of Large Language Models (LLMs) like ChatGPT by integrating an information retrieval system. This system empowers you to exert control over the data accessible to the LLM during response generation, ultimately improving the quality of generative AI. In essence, RAG enables LLMs to tap into additional data resources without the need for costly and time-consuming retraining. Creating your own LLM can incur expenses ranging from $450,000 to millions of dollars, with a training duration that could extend to months2.
Retrieval Augmented Generation Chatbot with Amazon Titan models
The first step of this process to generate text based on specific relevant data is to generate embeddings. These are numeric vectors that represent the textual data. Amazon’s Titan Embeddings model is specialized for this purpose and can generate the embeddings corresponding to your data.
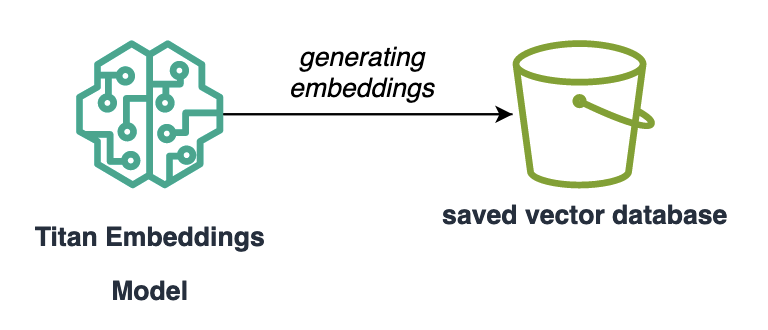
Once, the embeddings have been saved in a storage service such as S3, a lambda function can perform a similarity search using this vector database to retrieve only the data relevant to the user’s query. Next, this relevant data, also known as the context, is sent along with the user’s query to an LLM which will generate the appropriate response within the right context. Amazon’s Titan Text Express model is a suitable LLM for the job.

Using Amazon Bedrock Knowledge bases, you can provide your model with context without having to add the extra step of performing the similarity search. Once your data is added as is as a Knowledge base to the model of your choice with the choice of a model to handle embeddings, the vector database is created on your behalf, and relevant information is automatically found based on the user query and combined with the query to generate an accurate response from the LLM basaed on the relevant context.
Adding Speech to Text Layer
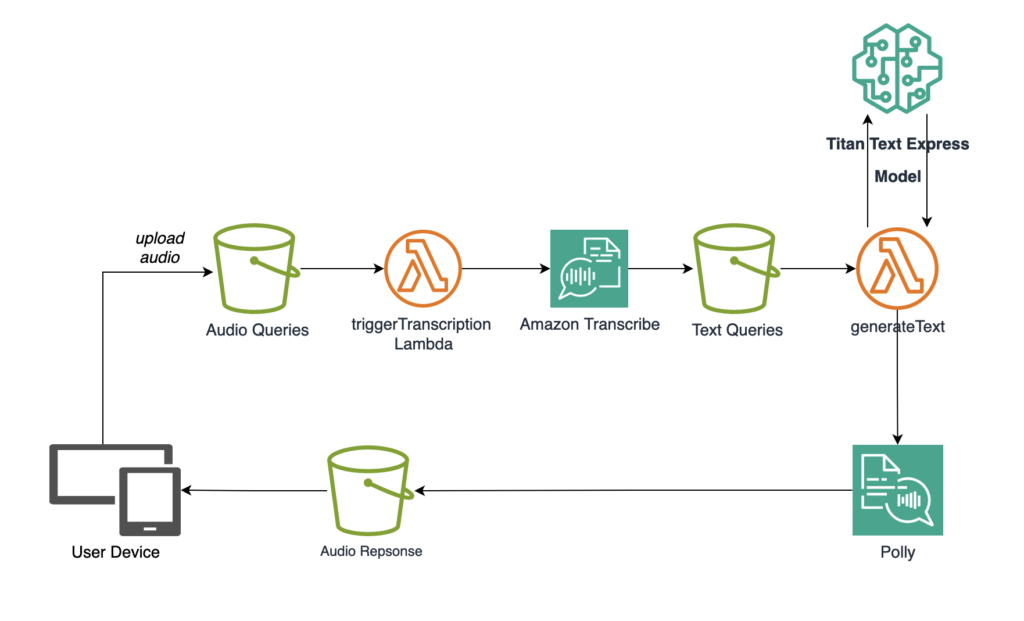
To go the extra mile, you can use Amazon Transcribe to accept the user’s query in audio format and Amazon Polly to return the response to the user in audio Format.
The architecture diagram below shows a high-level overview of the AWS services needed to create the well-rounded generative AI service to be integrated into existing business applications.
Setting Up the Source S3 bucket
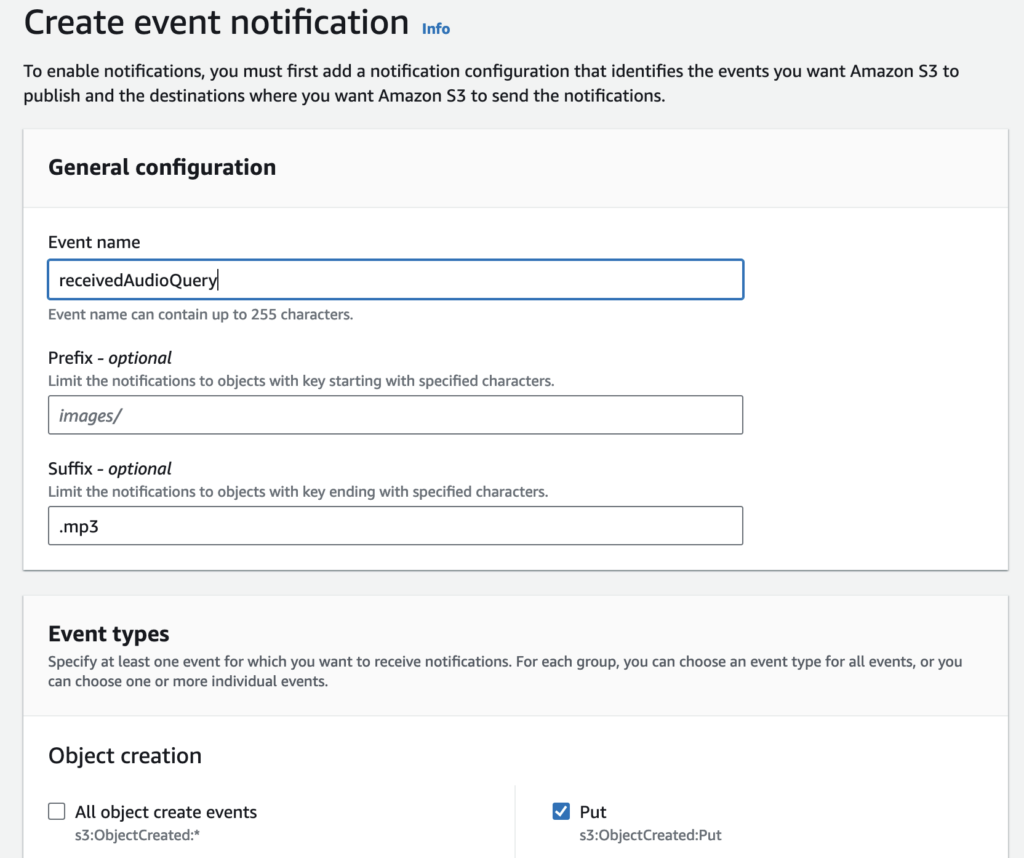
The first step is uploading the user’s queries in a consistent audio format to an S3 bucket from the user’s device/application. For this S3 bucket, event notifications are needed to automatically trigger the audio transformation. For this, we can choose the option to create Event Notifications in the Properties section of a designated S3 bucket.
We specify a suffix to match objects of a specific format to prevent mismatched formats during processing since we will need to declare this format later in the triggered transcription lambda function. For Event Types, we specify to match Put events according to the method used from the application to upload the audio file to the S3 bucket.
As a destination of the event notification, we select the Lambda function and choose the created trigger Transcription function.

This way, every time a new audio file is uploaded, it will be transcribed and sent to the LLM for a corresponding response.
triggerTranscription Lambda function
Before diving into this function’s code, we need to enure that it has the appropriate permissions to function correctly. It will need a role assigned to it that contains the following permissions to programmatically start a transcription job using Amazon Transcribe and to delete the job once done to clean up resources.
transcribe:StartTranscriptionJobtranscribe:GetTranscriptionJobtranscribe:DeleteTranscriptionJob
It should also have permissions to read S3 objects and to write to the output bucket specified in the transcription job (s3:GetObject and s3:PutObject permissions respectively).
The function’s code can be found below. It first retrieves the Amazon S3 bucket name and object key from the Amazon S3 event notification that triggered its execution. Then, it creates and starts a transcription job that converts the audio from the Amazon S3 bucket into text saved in a json file along with metadata and confidence measures in the output bucket. When the transcription is over, the lambda function cleans up resources by deleting the transcription job based on its name and status of execution.
import boto3
import time
import uuid
def lambda_handler(event, context):
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
#audio file location from the S3 event
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
#output bucket to save transcriptions with same name but .json extension
output_bucket = 'textQueriesBucket'
output_key = key.split(".")[0] + '.json'
job_name = f"TranscriptionJob_{str(uuid.uuid4())}" #unique name for each invocation
#starting transcription
response = transcribe.start_transcription_job(
TranscriptionJobName= job_name,
LanguageCode='en-US',
MediaFormat='mp3', # audio format mentioned previously
Media={
'MediaFileUri': f's3://{bucket}/{key}'
},
OutputBucketName=output_bucket,
OutputKey=output_key
)
#clean up resources
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)['TranscriptionJob']['TranscriptionJobStatus']
if status not in ('QUEUED', 'IN_PROGRESS'): #completed, failed, or cancelled
transcribe.delete_transcription_job(TranscriptionJobName=job_name)
break
time.sleep(5)
generateText Lambda function
The next step is to set up Event notifications on the textQueriesBucket to trigger the generateText Lambda function as done previously but without the suffix.
This Lambda function has to be assigned a role that contains the permission policies to read data from the textQueriesBucket S3 bucket and put objects to the audioResponsesBucket S3 bucket (s3:PutObject and s3:GetObject permissions). The function needs permission to call the Bedrock service as well. Finally, the function needs the polly:SynthesizeSpeech permission to access and use Amazon Polly service.
As for the function’s code:
import boto3
import json
def lambda_handler(event, context):
s3 = boto3.client('s3')
#Transcribe created json file location from the S3 event
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
file = s3.get_object(Bucket=bucket, Key=key)
content = file['Body'].read().decode('utf-8')
transcribed_text = json.loads(content)['results']['transcripts'][0]['transcript']
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2' #the region where you have access to the model
)
config = {
"modelId": "cohere.command-text-v14", #model id
"contentType": "application/json",
"accept": "*/*",
"body": {
"prompt": transcribed_text
}
}
response = bedrock_runtime.invoke_model(
body=json.dumps(config['body']),
modelId=config['modelId'],
accept=config['accept'],
contentType=config['contentType']
)
#getting text response from model
#this structure is specific to Cohere's Command
llm_text = json.loads(response.get('body').read())['generations'][0]['text']
#transforming the LLM's response to audio
polly = boto3.client('polly')
response = polly.synthesize_speech(
Text=llm_text,
OutputFormat='mp3',
VoiceId='Joanna' #can customize this, see AWS Documentation for voice IDs
)
bucket_name = 'audioResponsesBucket'
key = 'output.mp3'
s3.put_object(Bucket=bucket_name, Key=key, Body=response['AudioStream'].read())
This function retrieves the S3 object details (bucket and key) from the Lambda event object. Then, it reads the object and parses the transcription text from the object. The function then invokes the model available in Amazon Bedrock, passing it the user’s query transcribed. The response from the LLM is then transformed into speech using the Amazon Polly service which outputs the generated LLM text to MP3 format. Finally, the created audio file is uploaded to S3. At this point the audio output can be accessed from the bucket for further processing or sent back to the user using another Lambda function, depending on the application needs.
Note: For the call to Bedrock, you can use whichever model suits your business needs, but make sure to include the correct request structure expected by each model according to the AWS Documentation. Moreover, for the bedrock-runtime service to be available in boto3, you must have an updated version of the boto3 package in your Lambda function’s environment. Finally, to parse the response from a different model and save it in the llm_text variable, refer to the documentation of the model to know the structure of the response returned by each model.
Further Applications of Bedrock
The out-of-the box models offered by Amazon Bedrock come with a variety of functionalities across natural language processing (NLP), text generation, and other creative applications.
Incorporating these models into everyday business and creative workflows hints at infinite potential:
Translation Services: They power real-time language translation for international communication and content localization.
Customer Support: Chatbots and virtual assistants powered by these models can assist customers with inquiries and issue resolution in a wide range of industries.
Text Classification: Models can be used for email categorization, content filtering, and user profiling.
Art and Design: These models can generate unique artwork, designs, and creative content.
Data Augmentation: Generative AI can be used to create synthetic data for machine learning model training and data analysis.
What this means for the future
Generative AI holds immense potential, offering businesses a pathway to unlock new revenue streams. With Amazon Bedrock, you gain access to a versatile array of models that fuel creativity and innovation. The enhanced accessibility of these potent tools paves the way for a new era in generative AI applications, expediting progress and fostering exploration in artificial intelligence. As we’ve demonstrated, it’s possible to rapidly develop applications that leverage these models alongside other AWS services, expanding the capabilities of LLMs. With such robust resources at your disposal, the possibilities are limitless, and the future of generative AI is brighter than ever. Whether you seek inventive solutions, streamlined processes, or cutting-edge development tools, generative AI opens a world of opportunities. With Amazon Bedrock, the opportunities are greater than ever, and the barriers to entry are lower than ever, making it an opportunity you won’t want to miss.



